Adding Existing PDF Content
Add content from existing PDF documents to new created PDF documents using the ImportedPage and PdfDocument classes.
Use the ImportedPage class to import a page from an existing document. Use the PdfDocument and PdfPage class to extract content from an existing document and add to a new document.
The ImportedPage, PdfDocument, and PdfPage classes are part of the ceTe.DynamicPDF.Merger namespace.
Importing A Page
Import a existing page using the ImportedPage class. This class is a child of the Page class and encapsulates an imported page from an existing PDF document. Use the imported page as-is or add additional page elements to it. Then add the imported page to the document being constructed by a Document class instance.
If you find yourself needing to add an entire existing PDF (not only a page) to the PDF you are creating, then output the document you create as a finished PDF and then merge it with a document you need to append to your document to create a new merged PDF (see Document Merging).
The following example imports a page. It gets the imported page, adds a label to it, then inserts the page to a Document instance as the cover page to construct the new PDF.
Document document = new Document();
document.Pages.Add(new Page(PageSize.Letter));
ImportedPage page = new ImportedPage("DocumentA.pdf", 1);
Label lbl = new Label("Imported Page Text", 0, 0, 500, 0);
lbl.FontSize = 24;
lbl.TextColor = RgbColor.Navy;
page.Elements.Add(lbl);
document.Pages.Insert(0, page);
document.Draw(outputPath);
Dim document As New Document()
document.Pages.Add(New Page(PageSize.Letter))
Dim page As New ImportedPage("DocumentA.pdf", 1)
Dim lbl As New Label("Imported Page Text", 0, 0, 500, 0)
lbl.FontSize = 24
lbl.TextColor = RgbColor.Navy
page.Elements.Add(lbl)
document.Pages.Insert(0, page)
document.Draw(outputPath)
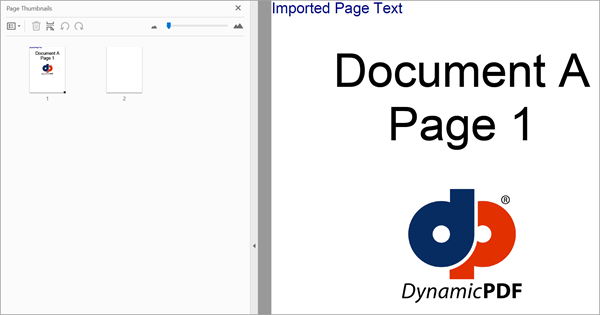 Figure 1. Importing a page and adding content.
Figure 1. Importing a page and adding content.
Extracting Existing PDF Content
Reuse existing PDF content in a Document instance using the PdfDocument and PdfPage classes.
To extract existing content from a PDF document, use the PdfDocument and PdfPage classes.
Refer to the Extracting Text documentation page for more information on extracting text from a PDF.
You can extract content from an existing PDF by loading it into a PdfDocument class and then examining/extracting its content. The PdfDocument class has methods and properties to get images, attachments, document metadata, text, fonts, and more.
The PdfDocument also has a Pages property that contains the document's pages as PdfPage instances.
Extracting from Document
The following example illustrates extracting an attached file and a bookmark from an existing PDF document and adding it to a Document instance to create a new PDF document.
PdfDocument pdfDoc = new PdfDocument("DocumentB.pdf");
Attachment attachment = pdfDoc.GetAttachments()[0];
EmbeddedFile embFile = new(attachment.GetData(), attachment.Filename, DateTime.Now);
PdfOutline outline = pdfDoc.Outlines[1];
Document document = new Document();
document.Pages.Add(new ImportedPage(pdfDoc.Pages[1]));
document.EmbeddedFiles.Add(embFile);
document.Outlines.Add(outline);
document.Draw(outputPath);
Dim pdfDoc As New PdfDocument("DocumentB.pdf")
Dim attachment As Attachment = pdfDoc.GetAttachments()(0)
Dim embFile As New EmbeddedFile(attachment.GetData(), attachment.Filename, DateTime.Now)
Dim outline As PdfOutline = pdfDoc.Outlines(1)
Dim document As New Document()
document.Pages.Add(New ImportedPage(pdfDoc.Pages(1)))
document.EmbeddedFiles.Add(embFile)
document.Outlines.Add(outline)
document.Draw(outputPath)
Note in the example above the Document could not add a PdfPage instance directly, but instead had to construct an ImportedPage instance from the PdfPage instance first.
Extracting from Page
If extracting text from a specific page, the following code illustrates extracting an image from a PdfPage and then adding the image to a Document instance's page.
Document document = new();
PdfDocument pdfDoc = new PdfDocument("DocumentB.pdf");
Page page = new Page(PageSize.Letter);
PdfPage pdfPage = pdfDoc.GetPage(1);
ImageInformation imageInfo = pdfPage.GetImages()[0];
Image image = new Image(imageInfo.GetImage().Data, 0, 0, .5F);
Label lbl = new Label("Extracted Image", 10, 400, 600, 0);
lbl.FontSize = 24;
lbl.TextColor = RgbColor.Navy;
page.Elements.Add(image);
page.Elements.Add(lbl);
document.Pages.Add(page);
document.Draw(outputPath);
Dim document As New Document()
Dim pdfDoc As New PdfDocument("DocumentB.pdf")
Dim page As New Page(PageSize.Letter)
Dim pdfPage As PdfPage = pdfDoc.GetPage(1)
Dim imageInfo As ImageInformation = pdfPage.GetImages()(0)
Dim image As New Image(imageInfo.GetImage().Data, 0, 0, 0.5F)
Dim lbl As New Label("Extracted Image", 10, 400, 600, 0)
lbl.FontSize = 24
lbl.TextColor = RgbColor.Navy
page.Elements.Add(image)
page.Elements.Add(lbl)
document.Pages.Add(page)
document.Draw(outputPath)
 Figure 2. Extracting image from a page.
Figure 2. Extracting image from a page.
Note that the PdfPage returns ImageInformation instances and not Image instances.